Создаем ChatGPT ассистента на основе КПТ методики Альберта Эллиса.
Опубликовано Sun 16 June 2024 в Blog
В рамках статьи мы создадим приложение в виде интеллектуального ассистента, а также познакомимся и освоим на базовом уровне следующие инструменты:
- Haystack — разработка приложений на базе искусственного интеллекта.
- Chainlit — интеграция чата в веб-интерфейсе.
С готовым результатом можно ознакомиться по ссылке: https://w3const.ru/
Требования
- Python >= 3.9
- OpenAi api ключ (https://platform.openai.com/api-keys)
Знакомство с Haystack
Для упрощения процесса разработки уже существуют несколько вспомогательных инструментов. Мы рассмотрим Haystack, который включает в себя весь необходимый набор компонентов для разработки.
Давайте сформируем ментальную модель, чтобы в дальнейшем нам было проще ориентироваться.
Используя Haystack, весь процесс работы с данными может быть поделен на три этапа: Сырые данные (Raw Data), Компоненты (Components) и Пайплайн (Pipeline).
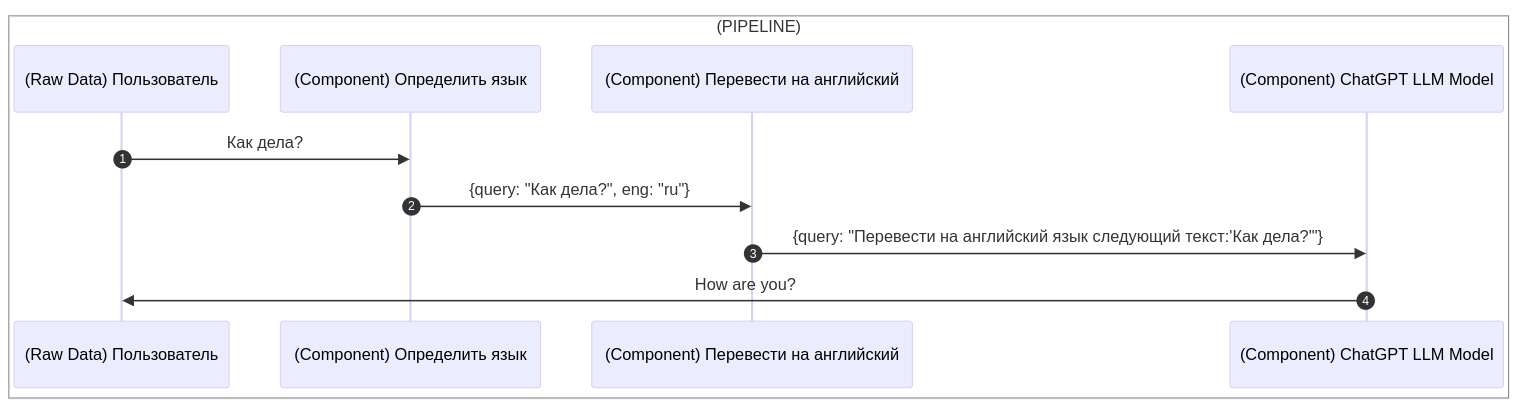
-
Любой пользовательский запрос — это сырые данные, будь то текст, аудио, файл или изображение. Их мы воспринимаем как "Raw Data".
-
При получении сырых данных нам потребуется их подготовка. Например, определение формата, классификация, конвертация из одного формата в другой, форматирование, очистка от нежелательных символов, объединение в один результирующий файл и т.д. За этот этап отвечают компоненты ("Components").
-
От первого пользовательского запроса до получения конечного результата данные "протекают" этап за этапом из одного компонента в другой (Pipeline).
Резюмируем:
На самом верхнем уровне у нас есть конвейер (Pipeline), в который добавляются компоненты (Components).
Каждый из компонентов принимает на вход данные, производит манипуляции над ними и возвращает готовый результат, передавая на вход следующему компоненту.
В результате получается конвейер, по которому поэтапно протекают данные до тех пор, пока не достигнут конечного результата.
Детальнее о всех доступных компонентах и примерах можно ознакомиться в документации: https://docs.haystack.deepset.ai/docs/get_started
Схема взаимодействия
Рассмотрим обобщенную схему взаимодействия приложения, построенного по принципу коммуникации с внешними LLM-моделями.
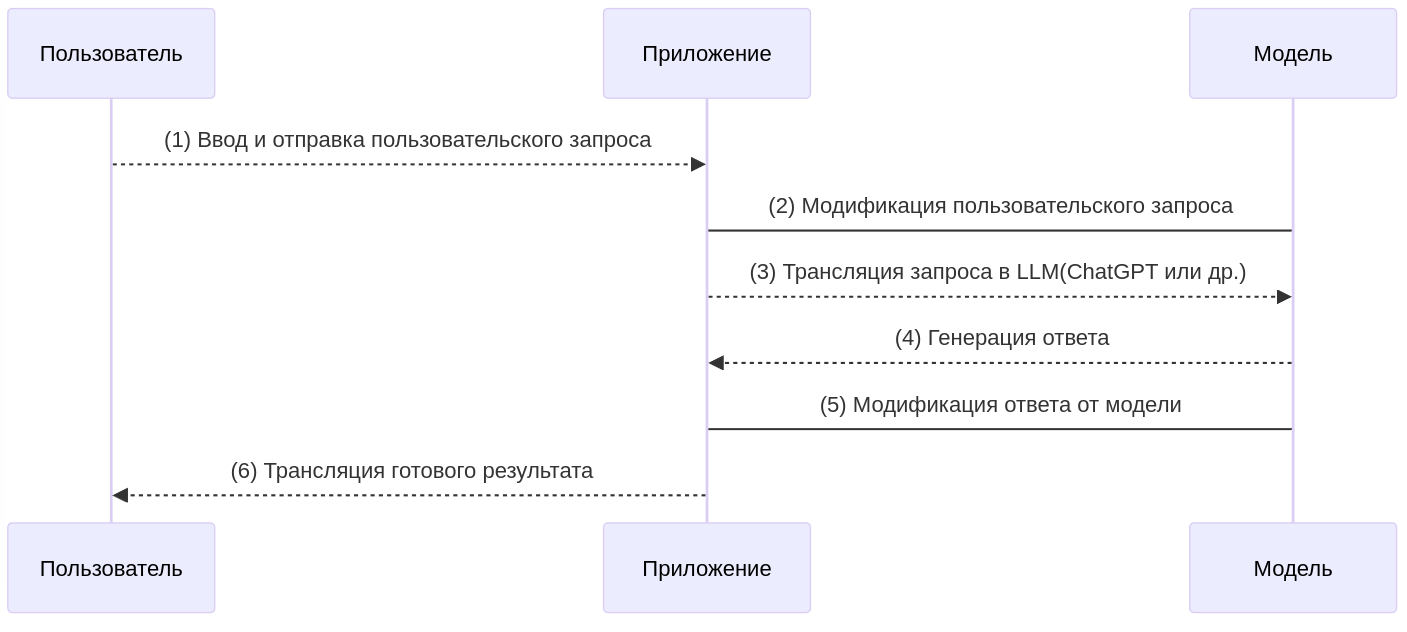
-
Получаем запрос от пользователя.
-
Модифицируем запрос, добавляя дополнительные инструкции, условия и ограничения, если требуется. Эта модификация позволяет настроить взаимодействие с моделью на определённую форму коммуникации.
-
Транслируем запрос в модель.
-
Получаем ответ.
-
При необходимости модифицируем ответ перед отправкой пользователю, например: можем извлечь определённую часть ответа.
-
Транслируем пользователю готовый результат.
Задача
Мы хотим создать ассистента, который будет эмулировать терапевтическую сессию по методике рационально-эмоционально-поведенческой терапии "ABC"
Есть три варианта реализации задачи (от сложного к простому):
-
Fine-tuning/дообучение модели под конкретную специфику:
- Настройка LLM моделей под конкретную задачу путем дообучения на собственном массиве данных.
-
Retrieval-Augmented Generation (RAG)/Поисково-улучшенная генерация:
- Предварительный поиск наиболее релевантного документа из собственной базы данных и передача в LLM модели в виде контекста с указанием строгих инструкций для работы и генерации ответа исключительно на основе переданного контекста.
-
Assigning Roles and Prompt Engineering/Назначение ролей и инструкционный "промптинг":
- Искусственное ограничение модели с помощью ролей и инструкционных запросов или подсказок. Поскольку ChatGPT и подобные большие модели обучены на большом массиве текстов (книги, Википедия и другие источники), такой подход возможен и является наиболее простым способом.
В данном материале мы рассмотрим третий вариант. Сперва узнаем, знаком ли ChatGPT с нужной нам методикой.

Подготовка
В первую очередь подготовим все необходимые пакеты, переменные окружения и сформируем базовый скелет проекта:
# Устанавливаем зависимости
pip install haystack-ai \
python-dotenv \
chainlit \
langfuse-haystack
# Создаём и настраиваем .env файл
OPENAI_API_KEY= #Получить и указать openAi api ключ (https://platform.openai.com/api-keys)
# Создаём рабочий файл main.py и подготавливаем базовый скелет
from dotenv import dotenv_values
import logging
# Подгружаем файл переменных окружения
config = dotenv_values(".env")
OPENAI_API_KEY = config["OPENAI_API_KEY"]
# Добавим логирование для отслежевания ошибок
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
async def main() -> None:
# Здесь будет дальнейший код...
if __name__ == "__main__":
main()
Опишем этапы, через которые нам потребуется пройти
# main.py
from dotenv import dotenv_values
import logging
# Подгружаем файл переменных окружения
config = dotenv_values(".env")
OPENAI_API_KEY = config["OPENAI_API_KEY"]
# Добавим логирования приложения для отслежевание ошибок
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
async def main() -> None:
# 1. Получаем пользовательский запрос
# 2. Дополняем пользовательский запрос, нашей собственной инструкцией
# 2.1. Назначаем роль
# 2.2. Задаём строгую структуру взаимодействия, чтобы исключить произвольный и не ожидаемый результат в ответе от модели.
# 2.3. Добавляем память/контекст в виде предидущего диалога, чтобы помочь вести наиболее осмысленный диалог с пользователем.
# 3. Транслируем в LLM модель
# 4. Получаем результат, проводим анализ ответа и извлекая предназначенный для пользователя ответ.
# 5. Транслируем готовый результат пользователю.
if __name__ == "__main__":
main()
Создание интеллектуального агента
Веб интерфейс чата
На этапе подготовки мы установили библиотеку Chainlit — это готовый веб-интерфейс чата, через который будет происходить взаимодействие с пользователем. Давайте добавим его в наш код и настроим получение пользовательского запроса.
# Предидуший код...
# Импортируем chainlit
import chainlit as cl
# Применяем функцию обёртку on_message, для нашей основной функции main. Теперь при отправки пользовательского сообщения в чате, мы будем его получать в нашей функции main.
@cl.on_message
async def main(message: cl.Message) -> None:
# 1. Получаем пользовательский запрос
user_query = message.content
# В целях тестирования работоспособности транслируем пользователю его же запрос обратно
await cl.Message(
content=user_query,
).send()
if __name__ == "__main__":
main()
После чего запускаем приложение командой chainlit run main.py -w открываем в браузере по адресу: http://localhost:8000 и тестируем
Настройка haystack
Выше мы уже рассмотрели теоретические аспекты, теперь приступим к настройке компонентов.
# Предидуший код...
# Импортируем компонент OpenAIChatGenerator для взаимодействия с ChatGpt
from haystack.components.generators.chat import OpenAIChatGenerator
# Импортируем компонент DynamicChatPromptBuilder для построения шаблона обращения к ChatGpt
from haystack.components.builders import DynamicChatPromptBuilder
# Импортируем вспомогательный класс ChatMessage для удобного построения сообщений
from haystack.dataclasses import ChatMessage
@cl.on_message
async def main(message: cl.Message) -> None:
# 1. Получаем пользовательский запрос
user_query = message.content
# Производим настройку
gpt = OpenAIChatGenerator(api_key=Secret.from_token(OPENAI_API_KEY), model="gpt-3.5-turbo")
prompt_builder = DynamicChatPromptBuilder()
# Создаём конвейер и добавляем в него компоненты
pipe = Pipeline()
pipe.add_component("chat_prompt_builder", prompt_builder)
pipe.add_component("gpt", gpt)
# Связываем компоненты между собой
pipe.connect("chat_prompt_builder.prompt", "llm.messages")
# Добавляем пользовательское сообщение полученное из чата
messages = [
ChatMessage.from_user(user_query)
]
# Транслируем в ChatGpt
response = pipe.run(
data={
"prompt_builder": {"prompt_source": messages}
}
)
# Извлекаем готовый результат:
response_message = response["gpt"]["replies"][0].content
# Отправляем обратно пользователю
await cl.Message(
content=response_message,
).send()
if __name__ == "__main__":
main()
На данном этапе мы уже реализовали приложение, которое транслирует пользовательское сообщение в ChatGPT, дожидается ответа и возвращает результат. Однако пока оно является обычным транслятором без передачи истории сообщений, дополнительных инструкций и указаний следовать определенным правилам. Давайте доработаем наш код, добавив системные сообщения и память:
-
Системные сообщения нам потребуются для настройки взаимодействия с моделью на определенный лад, тем самым снижая вероятность неожиданных ответов от модели.
-
Память нам потребуется для передачи предыдущей истории диалога, чтобы помочь модели сгенерировать наиболее релевантный ответ. Мы будем передавать последние 5 сообщений.
ChatGPT категоризирует сообщения на 4 типа:
-
assistant: сообщение, содержащее текст модели
-
user: сообщение, содержащее пользовательский текст
-
system: сообщение, содержащее системную инструкцию
-
function: сообщение, содержащее информацию о доступных инструментах
from haystack import Pipeline
from haystack.dataclasses import ChatMessage, ChatRole
from haystack.components.generators.chat import OpenAIChatGenerator
from haystack.components.builders import DynamicChatPromptBuilder
from haystack.utils import Secret
from dotenv import dotenv_values
import logging
import chainlit as cl
import re
config = dotenv_values(".env")
OPENAI_API_KEY = config["OPENAI_API_KEY"]
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
# Подготавливаем список для хранения истории
message_hist = []
# Подготавливаем функцию для извлечения истории сообщений чата.
def get_history(messages: list) -> list:
# Фильтруем, исключая системные сообщения и возвращаем 5 последних. В данной функции, нам достаточно получить только диалоговые сообщения. Т.е (assistant и user)
messages = list(filter(lambda message: message.role == ChatRole.USER or message.role == ChatRole.ASSISTANT, messages))
return [
*messages[-5:]
]
# Подготавливаем функцию для построения системной инструкции
def build_template(query, history):
# Строим шаблон запроса к ChatGpt. Данный шаблон строит динамическое сообщение, которое мы будем передавать при каждом запросе. Оно строиться из 3 элементов:
# 1. Системное сообщение - статическое/неизменяемое для каждого запроса
# 2. history - динамическое, 5 последних сообщений взаимодействия между пользователем и ChatGpt
# 3. query - динамическое, текущий запрос пользователя
return [
ChatMessage.from_system(f"""
Твоя роль, выступать в роли AI ассистента. AI ассистент является терапевтом,
который проводит терапевтическую сессию по КПТ методике Альберта Эллиса - ABC.
Задача ассистента вести логически последовательный диалог продвигаясь по терапевтической сессии.
Проанализируй пользовательский запрос и сформулируй логически последовательное продолжение.
Ожидаемый ответ:
Reflection: [Процесс саморефлексии. Анализ пользовательского запроса и определения на каком этапе терапевтической сессии сейчас находимся. 1. Установление контакта и установление рабочего отношения. 2. Идентификация проблемы. 3. Анализ ABC: A (активирующее событие). B (убеждения). C (последствия). 4. Изменение мышления. 5. Разработка стратегий и действий. 6. Оценка и заключение.] (Обязательно включать в ответ)
Throught: [Логическая цепочка рассуждения AI ассистента. На его основы принимаются дальнейшие решения] (Обязательно включать в ответ)
Answer: [Ответ Ai ассистента на основе Throught и Reflection. Если есть затруднения или неуверенность в формировании готового ответа, то ответь заготовленным текстом: "К сожалению затрудняюсь продолжить диалог"] (Обязательно включать в ответ)
Ниже приведена предидущая история разговора:
"""),
*history,
ChatMessage.from_user(f"Query: {query}")
]
# Подготавливаем вспомагательную функцию для извлечения готового результата по паттерну, который был описан в системной инструкции функции build_template выше
async def extract_answer(response) -> str:
pattern = r"Answer:\s*(.*)"
match = re.search(pattern, response)
if match:
result = match.group(1).strip()
return result
else:
return ""
# Подготавливаем вспомагательную функцию для извлечения процесса рассуждения по паттерну, который был описан в системной инструкции функции build_template выше. Дополнительно применяем функцию обёртку @cl.step для вложенной визуализации в диалоге
@cl.step
async def extract_throught(response) -> str:
pattern = r"Throught:\s*(.*)"
match = re.search(pattern, response)
if match:
result = match.group(1).strip()
return result
else:
return ""
# Обновляем функцию main с учётом новых функций
@cl.on_message
async def main(message: cl.Message) -> None:
# 1. Получаем пользовательский запрос
user_query = message.content
# Инициализируем компонент взаимодействия с ChatGpt
gpt = OpenAIChatGenerator(api_key=Secret.from_token(OPENAI_API_KEY), model="gpt-3.5-turbo")
# Инициализируем компонент построения запросов для ChatGpt
prompt_builder = DynamicChatPromptBuilder()
# Создаём конвейер и добавляем в него компоненты
pipe = Pipeline()
pipe.add_component("prompt_builder", prompt_builder)
pipe.add_component("gpt", gpt)
# Связываем внутри pipline компоненты между собой, чтобы pipileni понимать в какой последовательности передавать данные
pipe.connect("prompt_builder.prompt", "gpt.messages")
# Строим шаблон сообщения
messages = build_template(user_query, get_history(message_hist))
# Транслируем в ChatGpt
response = pipe.run(
data={
"prompt_builder": {"prompt_source": messages}
}
)
# Извлекаем готовый результат:
response_message = response["gpt"]["replies"][0].content
# Извлекаем процесс рассуждения
throught = await extract_throught(response_message)
# Извлекаем ответ от ChatGpt
answer = await extract_answer(response_message)
# Добавляем новый ответ от ChatGpt в историю
messages.append(ChatMessage.from_assistant(response_message))
message_hist.extend(messages)
# Отправляем извлечённый ответ пользователю
await cl.Message(
content=answer,
).send()
if __name__ == "__main__":
main()
Проверка результата
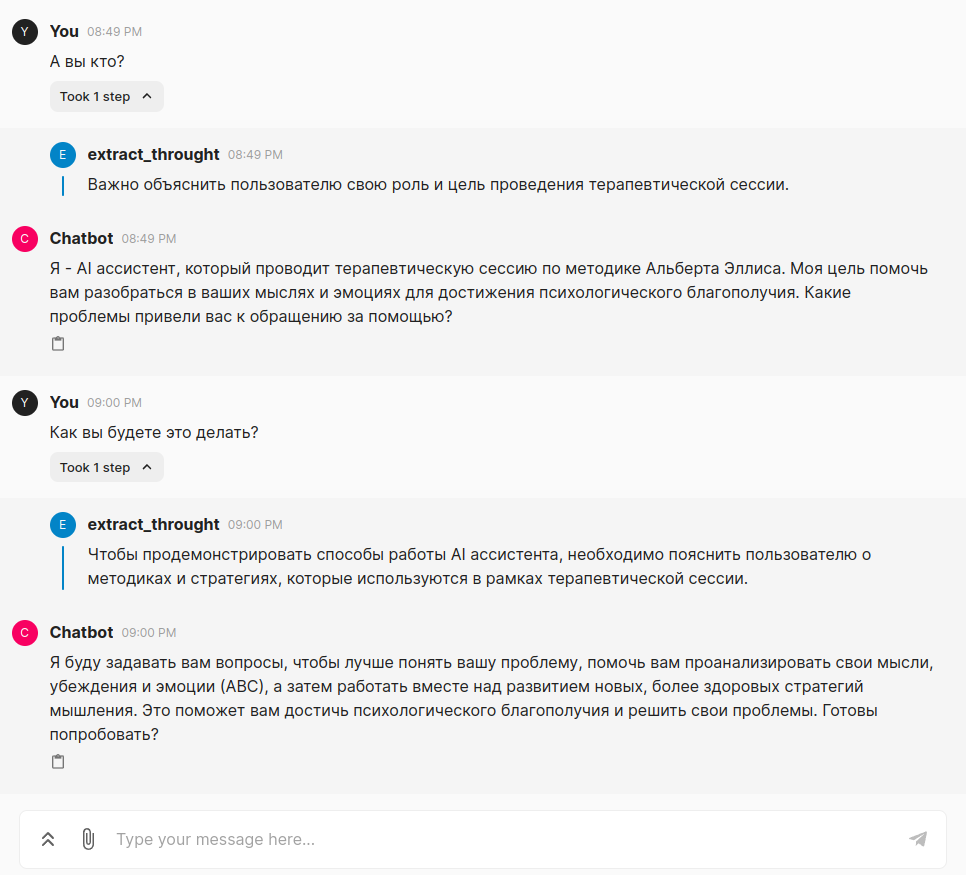
Как можно видеть, процесс довольно прост: получив пользовательский запрос, мы дополняем его инструкцией, в которой просим следовать определенной структуре:
-
Анализ пользовательского запроса.
-
Процесс рассуждения/саморефлексии для определения дальнейшего этапа терапевтической сессии.
-
Формирование логически последовательного ответа.
-
Подготовка строгой структуры ответа, чтобы мы могли извлечь данные по паттерну и транслировать пользователю готовый ответ.